"Failure Predicted"
SAS and SATA support hot-swap.
However, on LSI/Dell controllers, you should force the pred fail drive OFFLINE before removing it.
Once you force it offline, you should replace it "hot".
If pred fail drives are not actually offline when you remove them, it can cause the controller to flag the new drive with the same pred fail flag, which will then require a rescan (reboot) to clear it and show the drive as healthy.
The drive can be forced offline from the OS using OpenManage Server Administrator (OMSA).
If the new drive does not begin rebuilding automatically, then assign it as a hot-spare in OMSA.
=====================================
Add Disk as hot spare
Convert to RAID Capable Disks
State "Non-RAID" -> "Ready"
=====================================
Automatic Replace Member With Predicted Failure
A Replace Member operation can occur when there is a SMART predictive failure reporting on a physical disk in a
virtual disk. The automatic Replace Member is initiated when the first SMART error occurs on a physical disk that is part
of a virtual disk. The target disk needs to be a hot spare that qualifies as a rebuild disk. The physical disk with the
SMART error is marked as failed only after the successful completion of the Replace Member. This avoids putting the
array in degraded status.
If an automatic Replace Member occurs using a source disk that was originally a hot spare (that was used in a rebuild),
and a new disk added for the Replace Member operation as the target disk, the hot spare reverts to the hot spare state
after a successful Replace Member operation.
Using "Replace Member" And Revertible Hot Spares
The Replace Member functionality allows a previously commissioned hot spare to be reverted to a usable hot spare.
When a disk failure occurs within a virtual disk, an assigned hot spare (dedicated or global) is commissioned and begins
rebuilding until the virtual disk is optimal. After the failed disk is replaced (in the same slot) and the rebuild to the hot
spare is complete, the controller automatically starts to copy data from the commissioned hot spare to the newlyinserted
disk. After the data is copied, the new disk is a part of the virtual disk and the hot spare is reverted to being a
ready hot spare. This allows hot spares to remain in specific enclosure slots. While the controller is reverting the hot
spare, the virtual disk remains optimal.
NOTE: The controller automatically reverts a hot spare only if the failed disk is replaced with a new disk in the
same slot. If the new disk is not placed in the same slot, a manual Replace Member operation can be used to revert
a previously commissioned hot spare.
NOTE: A Replace Member operation typically causes a temporary impact to disk performance. Once the operation
completes, performance returns to normal.
Using Persistent Hot Spare Slots
Once enabled, any slots with hot spares configured automatically become persistent hot spare slots. If a hot spare disk
fails or is removed, a replacement disk that is inserted into the same slot automatically becomes a hot spare with the
same properties as the one it is replacing.
* A dedicated hot spare is used before a global hot spare is used. You can create dedicated hot spares or delete them on the VD Mgmt screen.
"Disk Group #" -> "<F2>"
"Manage Ded. HS"
Dedicated hot spare
A dedicated hot spare is an unused backup disk that is assigned to a single virtual disk.
When a physical disk in the virtual disk fails, the hot spare is activated to replace the failed physical disk
without interrupting the system or requiring your intervention.
Upgrade firmware
Download
DELL PERC H700 adpt v12.10.6-0001, A12
Download Link:
http://www.dell.com/support/home/us/en/19/Drivers/DriversDetails?driverId=5PRJ8
Last Updated
23 Jul 2013
MD5:
6b0560de71cfa49192aec16b7003b57a
Compatible Systems:
PowerEdge R410
Upgrade
chmod 700 SAS-RAID_Firmware_5PRJ8_LN_12.10.6-0001_A12.BIN
# check info
./FRMW_LX_RXXXXXX.BIN --version
# upgrade:
./FRMW_LX_RXXXXXX.BIN
* Upgrade е®ҢиҰҒ reboot дё»ж©ҹ
Degraded Backplane Error shows in OSMA
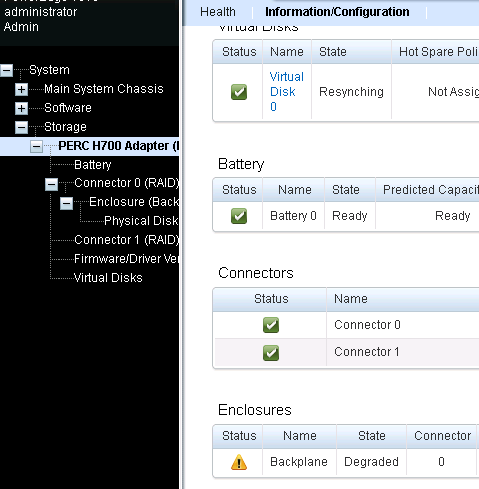
Fix:
restart management agents (DSM SA Data Manager)
sc stop dcstor32 && sc start dcstor32
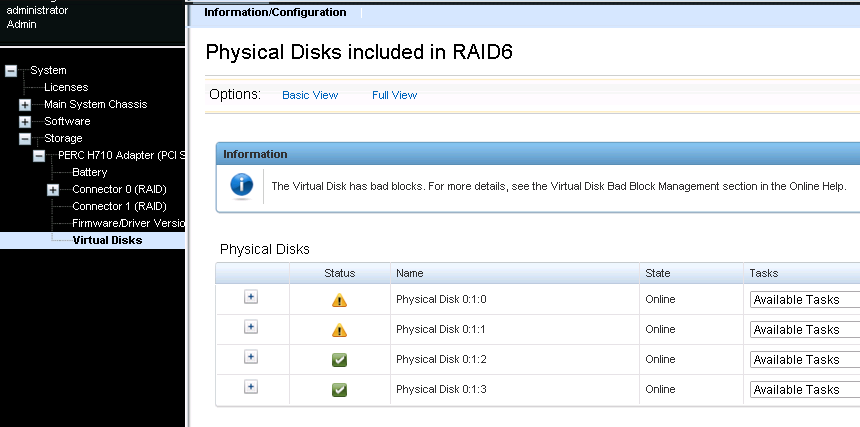
Virtual Disk Bad Blocks
жғ…жіҒ
After a disk failure we had a message saying
"The Virtual Disk has bad blocks. For more details, see the Virtual Disk Bad Block Management section in the Online Help."
Virtual disk bad blocks are bad blocks on one or more member physical disks.
The read operation on the virtual disks having bad blocks may fail.
Recovering a physical disk bad block depends on the RAID level and state of the virtual disk.
If a virtual disk is redundant, the controller can recover a bad block on a physical disk.
If a virtual disk is not redundant, then the physical disk bad block results in a virtual disk bad block.
RAID 5 иҲҮ RAID 6 йҒҮ Bad Block еҲҶеҲҘ
RAID 5
State: Ready
The controller regenerates data from the peer disks and sends a Write to the bad block.
The disk then remaps the Logical Block Addressing (LBA) to another physical location.
The problem is resolved.
State: Degraded
The controller cannot regenerate data from the peer disks because one drive is missing.
This results in a virtual disk bad block.
RAID 6
State: Ready
The controller regenerates data from peer disks and sends a Write to the bad block.
The disk then remaps the Logical Block Addressing (LBA) to another physical location.
The problem is resolved.
State: Degraded (two failed/missing physical disks)
The controller cannot regenerate data from the peer disks.
This results in a virtual disk bad block.
"Clear Virtual Disk Bad Blocks" task
![]()
1. performing a backup of the virtual disk with the Verify
a) The backup operation completes without errors.
This indicates that there are no bad blocks on the written portion of your virtual disk.
b) The backup operation fails on one or more files.
restore the file from a previous backup
2. execute the "Clear Virtual Disk Bad Blocks" task
Run Patrol Read (under Virtual Disk Tasks in OMSA) and
check the system event log to ensure that no new bad blocks are found.
H310 RAID5 Slow
RAID5 on SSD
VD bad blocks
еҮәзҸҫзҡ„жғ…жіҒ
жғ…жіҒ: 4 HDD зө„жҲҗ RAID5, жІ’жңү hot spare. 當жӣҙжҸӣе…¶дёӯдёҖйҡ»еЈһ HDD еҫҢеҮәзҸҫ bad blocks
2048 Thu Aug 19 08:39:35 2021 Storage Service Device failed: Physical Disk 0:0:3 Controller 0, Connector 0
2057 Thu Aug 19 08:39:36 2021 Storage Service Virtual disk degraded: Virtual Disk 0 (Virtual Disk 0) Controller 0 (PERC H700 Adapter)
2350 Fri Aug 20 03:10:46 2021 Storage Service There was an unrecoverable disk media error during the rebuild or recovery operation: Physical Disk 0:0:2 Controller 0, Connector 0
2049 Tue Aug 24 10:49:47 2021 Storage Service Physical device removed: Physical Disk 0:0:3 Controller 0, Connector 0
2052 Tue Aug 24 10:54:15 2021 Storage Service Physical device inserted: Physical Disk 0:0:3 Controller 0, Connector 0
2121 Tue Aug 24 10:54:16 2021 Storage Service Device returned to normal: Physical Disk 0:0:3 Controller 0, Connector 0
2065 Tue Aug 24 10:54:16 2021 Storage Service Physical disk Rebuild started: Physical Disk 0:0:3 Controller 0, Connector 0
2124 Tue Aug 24 11:26:37 2021 Storage Service Redundancy normal: Virtual Disk 0 (Virtual Disk 0) Controller 0 (PERC H700 Adapter)
2092 Tue Aug 24 11:26:36 2021 Storage Service Physical disk Rebuild completed: Physical Disk 0:0:3 Controller 0, Connector 0
[Fix]
# жё…йҷӨжҺ§еҲ¶еҷЁ 1 дёҠзҡ„иҷӣ擬зЈҒзӣӨ 4 дёҠзҡ„еЈһеЎҠ
# clearing the blocks shouldn't endanger the data
omconfig storage vdisk action=clearvdbadblocks controller=1 vdisk=4
P.S.
consistency check pass ?
Passing the consistency check means that
it did not have any blocks with bad data on multiple drives and was able to remap them.
(It does not mean there were not any bad blocks in written areas)
The consistency check will verify the data in each block.
When it finds bad blocks it will check the parity data or mirrored data, depending on the RAID level.
It will then remap the bad block.
PERC H710 on ESXi 5.5
еҸҜд»Ҙе®үиЈқ PERCCLI utility жҹҘзңӢ RAID зҡ„жғ…жіҒ
дёӢијү: DELL зҡ„е®ҳз¶І
Install
esxcli software vib install -v /vmfs/volume/datastore1/vmware-perccli-xxx.xxxx.xxxx.xxxx.vib --no-sig-check
Usage
cd /opt/lsi/perccli
# Shows a summary of controller and controller-associated information.
./perccli show
# help
./perccli show help
# VD LIST, PD LIST
./perccli /c0 show
./perccli /cx[/ex]/sx show
./perccli /cx[/ex]/sx show all