зӣ®йҢ„
еӨўжғіе®¶жҙ»дёҖиә«, еӯёз„Ўйҷҗ~ еӨўдёҚжҒҜ, еҝғдёҚеҖҰ~ |
|
|
еӯёиЎ“еҸҠиіҮжәҗзҡ„дәӨжөҒең’ең° ^_^ Qemu Monitor interfaceз”ұ datahunter еңЁ дёҖ, 24/09/2012 - 23:11 зҷјиЎЁ
зӣ®йҢ„
»
usbipз”ұ datahunter еңЁ дёҖ, 24/09/2012 - 23:06 зҷјиЎЁжңҖеҫҢжӣҙж–°: 2015-05-20 Homepage http://usbip.sourceforge.net/ ж”ҜжҸҙ
Diagram: client host Server »
ddrescueз”ұ datahunter еңЁ дә”, 21/09/2012 - 19:32 зҷјиЎЁжңҖеҫҢжӣҙж–°: 2022-10-27 д»Ӣзҙ№HomePage: http://www.gnu.org/software/ddrescue/ If you use the logfile feature of ddrescue, the data is rescued very efficiently, (only the needed blocks are read). Also you can interrupt the rescue at any time and resume it later at the same point. ddrescue does not write zeros to the output when it finds bad sectors in the input, (жүҖд»Ҙ當дёҚзҗҶжңғ bad sector жҷӮ zero йӮЈдҪҚзҪ®дёҖж¬Ў) and does not truncate the output file if not asked to. So, every time you run it on the same output file, it tries to fill in the gaps without wiping out the data already rescued. ddrescue manages efficiently the status of the rescue in progress and tries to rescue the good parts first, scheduling reads inside bad (or slow) areas for later. This maximizes the amount of data that can be finally recovered from a failing drive. * If the damaged drive is not listed in /dev, then you cannot rescue it. At least not with ddrescue. nor is related to dd try to minimize head movement to minimize drive damage.
Recovery зҡ„йҒҺзЁӢ(Algorithm)
Recovery зҡ„йҒҺзЁӢдёҖе…ұжңү 3 еҖӢ Phase, жңҖзөӮеҸӘжңү Good ("+") / Bad Block ("-") жөҒзЁӢ: non-tried -> non-trimmed -> non-scraped -> bad-sector
First phase - Copying Copying is done in up to 5 passes. The first pass It reads the non-tried parts of the input file, marking the failed blocks as non-trimmed and skipping beyond them. The second pass It delimits the blocks skipped by the first pass. The third and fourth passes It read the blocks skipped due to slow areas (if any) by the first two passes, in the same direction that each block was skipped. For each block, passes 2 to 4 skip the rest of the block after finding the first error in the block. The last pass It is a sweeping pass, with skipping disabled. The copying direction is reversed after each pass until all the rescue domain is tried. Only non-tried areas are read in large blocks. Trimming, scraping and retrying are done sector by sector. Each sector is tried at most two times; the first in this phase as part of a large block read, the second in one of the phases below as a single sector read. The purpose of the multiple passes is to delimit large bad areas fast, recover the most promising areas first, keep the mapfile small, and produce good starting points for trimming. Second phase - Trimming Trimming is done in one pass. For each non-trimmed block, read forwards one sector at a time from the leading edge of the block until a bad sector is found. Then read backwards one sector at a time from the trailing edge of the block until a bad sector is found. Then mark the bad sectors found (if any) as bad-sector, and mark the rest of the block as non-scraped without trying to read it. Third phase - Scraping Scrape together the data not recovered by the copying or trimming phases. Scraping is done in one pass. Each non-scraped block is read forwards, one sector at a time. Any bad sectors found are marked as bad-sector. зӣ®йҢ„
»
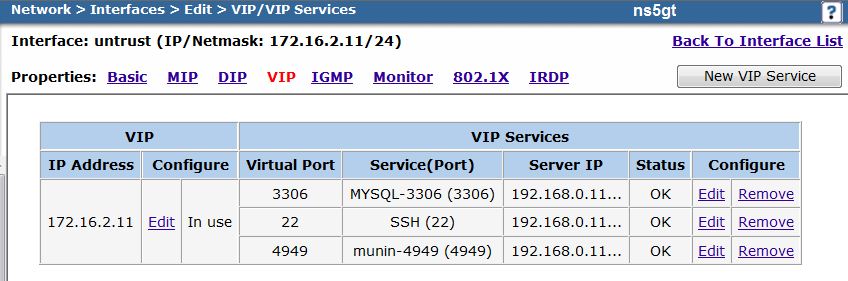
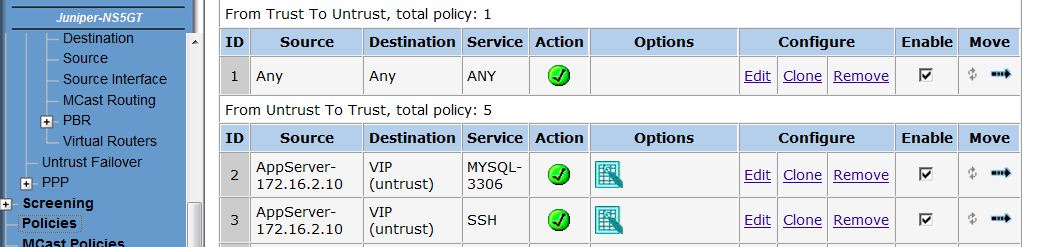
netscreenз”ұ datahunter еңЁ дёү, 19/09/2012 - 18:08 зҷјиЎЁ
»
|