жЬАеЊМжЫіжЦ∞: 2024-06-25
зЫЃйМД
- дїЛзіє
- Recovery зЪДйБОз®Л (Algorithm)
- OS Read Timeout
- Install
- Usage
- Output Info
- Basic Example
- Rescue some key disc areas
- Retry & Skip & Reopen
- Direct disc access (-d)
- Logfile Structure
- Example: Recovery CD
- Fill Mode (--fill)
- ddrescueview
- Display Settings
дїЛзіє
HomePage: http://www.gnu.org/software/ddrescue/
----
ddrescue is not a derivative of dd
----
If you use the logfile feature of ddrescue, the data is rescued very efficiently, (only the needed blocks are read).
Also you can interrupt the rescue at any time and resume it later at the same point.
So, every time you run it on the same output file, it tries to fill in the gaps without wiping out the data already rescued.
ddrescue does not write zeros to the output when it finds bad sectors in the input,
and does not truncate the output file if not asked to.
(жЙАдї•зХґдЄНзРЖжЬГ bad sector жЩВ zero йВ£дљНзљЃдЄАжђ°)
----
ddrescue manages efficiently the status of the rescue in progress and tries to rescue the good parts first,
scheduling reads inside bad (or slow) areas for later.
This maximizes the amount of data that can be finally recovered from a failing drive.
* If the damaged drive is not listed in /dev, then you cannot rescue it. At least not with ddrescue.
----
Newer versions try to minimize head movement to minimize drive damage. (Ver >= 1.19)
Recovery зЪДйБОз®Л (Algorithm)
Recovery зЪДйБОз®ЛдЄАеЕ±жЬЙ 6 еАЛ Phase, жЬАзµВеП™жЬЙ Good ("+") / Bad Block ("-")
жµБз®Л: non-tried -> non-trimmed -> non-scraped -> bad-sector
- non-tried # Size of the part of the rescue domain pending to be tried.
- non-trimmed # Size of the part of the rescue domain pending to be trimmed.
- non-scraped # Size of the part of the rescue domain pending to be scraped.
Phase 1 - Copying as much data as possible
Phase 1 зЪДзЫЃзЪД
Copying is done in up to 5 passes.
The purpose of the multiple passes is to delimit large bad areas fast,
recover the most promising areas first, keep the mapfile small,
and produce good starting points for trimming.
* Only non-tried areas are read in large blocks.
Trimming(P2), scraping(P3), and retrying(P4) are done sector by sector.
The first pass
It reads the non-tried parts of the input file,
marking the failed blocks as non-trimmed and skipping beyond them.
Parameter: --cpass=1
Copying non-tried blocks... Pass 1 (forwards)
The second pass
runs in the opposite direction as the first pass and
delimits the blocks skipped by the first pass.
* The first two passes also skip beyond slow areas.
The areas skipped are tried later in one or three additional passes (before trimming).
Parameter: --cpass=2
Copying non-tried blocks... Pass 2 (backwards)
The third and fourth passes
It read the blocks skipped due to slow areas (if any) by the first two passes,
in the same direction that each block was skipped.
For each block, skip the rest of the block after finding the first error in the block.
The last pass
It is a sweeping pass, with skipping disabled.
Phase 2 еПК 3 жШѓдЄАйљКеЗЇзПЊжЙНжЬЙжХИ
Phase 2 - Trimming
Trimming is done in one pass.
For each non-trimmed block, read forwards one sector at a time from the leading edge of the block until a bad sector is found.
Then read backwards one sector at a time from the trailing edge of the block until a bad sector is found.
Then mark the bad sectors found (if any) as bad-sector, and mark the rest of the block as non-scraped without trying to read it.
Then mark the bad sectors found (if any) as bad-sector,
and mark the rest of the block as non-scraped without trying to read it.
Phase 3 - Scraping
Scraping is done in one pass.
Scrape together the data not recovered by the copying or trimming phases.
Each non-scraped block is read forwards, one sector at a time. Any bad sectors found are marked as bad-sector.
Phase 4 - Retrying
Optionally try to read again the bad sectors until the number of retry passes specified is reached.
(Every bad sector is tried only once in each pass)
The direction is reversed after each pass
Phase 5(Optionally) - write a mapfile for later use
If the output file is a regular file created by ddrescue, the areas marked as bad-sector will contain zeros.
If it is a device or a previously existing file, the areas marked as bad-sector will still contain the data previously present there.
Disk Read Timeout (OS)
"dd" дњВжЬГдљњзФ®з≥їзµ±зЪД timeout еПК eh_timeout и®≠еЃЪ
timeout
# To control the command timer
/sys/block/<deviceName>/device/timeout # SCSI default: 30
eh_timeout
# The timeout value for "TEST UNIT READY" and "REQUEST SENSE" commands used by the SCSI error handling code.
/sys/block/<deviceName>/device/eh_timeout # Default: 10
дњЃжФє
e.g.
echo 3 > /sys/block/sdf/device/timeout
echo 3 > /sys/block/sdf/device/eh_timeout
Install
apt-get install ddrescue
ddrescue -V
GNU ddrescue 1.16
Unit
s = sectors, k = 1000, Ki = 1024, M = 10^6, Mi = 2^20
Usage
ddrescue [options] infile outfile [logfile]
-i <bytes> # starting position in input file (Default 0)
-s <bytes> # maximum size of input data to be copied
# дљњзФ®еЊМ, "pct rescued:" жШѓ "-s" зЪДдїљйЗП
-b softbs # sector size of input device [Default 512]
-f, --force # зХґзЫЃж®ЩжШѓ Device жЩВе∞±и¶БеК†еЃГ
-A, --try-again # mark non-split, non-trimmed blocks as non-tried
# Try this if the drive stops responding and ddrescue immediately starts scraping failed blocks when restarted.
-M, --retrim # Mark all failed blocks inside the rescue domain as non-trimmed before beginning the rescue.
-p, --preallocate # preallocate space on disc for output file
# If preallocation succeeds, rescue will not fail due to lack of free space on disc.
-c, --cluster-size= # Number of sectors to copy at a time. Defaults to "64 KiB / sector_size"
e.g.
-c 32 -b 4096 # жѓП 128 KiB жКДдЄАжђ° (32 x 4k)
Output Info
e.g.
Current status
ipos: 852214 MB, non-trimmed: 3653 kB, current rate: 3276 B/s
opos: 852214 MB, non-scraped: 0 B, average rate: 43441 kB/s
non-tried: 1310 GB, bad-sector: 8192 B, error rate: 0 B/s
rescued: 636641 MB, bad areas: 2, run time: 2h 58m 42s
pct rescued: 32.70%, read errors: 70, remaining time: 5h 26m
slow reads: 471, time since last successful read: 0s
Copying non-tried blocks... Pass 1 (forwards)
ipos
Input position. where data are being currently read from.
opos
Output position. where data are being currently written to.
non-tried
Size of the part of the rescue domain pending to be tried. This is the sum of the sizes of all the non-tried blocks.
This is the sum of the sizes of all the non-trimmed, non-scraped, and bad-sector blocks.
bad-sector
It increases during the trimming and scraping phases, and may decrease during the retrying phase.
as ddrescue retries the bad-sector blocks, the good data found may divide them into smaller blocks,
decreasing the total error size but increasing the number of bad areas.
bad areas
Number of separate bad-sector blocks inside the rescue domain.
Basic Example
1) е∞З sda3 иЃКжИР image
dd_rescue /dev/sda3 /media/backup/sda3.img ddrescue.log
2) Disk to Disk Clone
# sda -> sdz
# '-f' Force overwrite of outfile.
Needed when outfile is not a regular file, but a device or partition.
ddrescue -f -n -N /dev/sda /dev/sdz /root/ddrescue.log
# зФ® zero еОїжЄЕжЬЙеХПй°МзЪД Block
ddrescue -f /dev/zero /dev/sdz /root/ddrescue.log
2) zip иµЈеЃГ / transfer to remote
ddrescue /dev/sda1 - | bzip2 > /dir/file.img.bz2
3) transfer to remote
ddrescue /dev/sda1 - |
ssh user@remote "cat - > /remote/destination/file.img"
Rescue some key disc areas
Opts
'-i bytes' / '--input-position=bytes'
Starting position of the rescue domain in infile, in bytes. Defaults to 0.
'-s bytes' / '--size=bytes'
Maximum size of the rescue domain, in bytes. It limits the amount of input data to be copied.
e.g.
жЗЙзФ®: еИЖе§Ъ Part recovery
# зФ± 0 byte дљНзљЃйЦЛеІЛ copy 200GiB
ddrescue -i -s200GiB /dev/sde sde.img ddrescue.log
# зФ± 30Gib дљНзљЃйЦЛеІЛ copy 10GiB
ddrescue -i30GiB -s10GiB /dev/sde sde.img ddrescue.log
Notes
Unit дЄНжФѓжПіе∞ПжХЄйїЮ, жЙАдї• 1.7TiB и¶БеѓЂжИР 1700GiB
Retry & Skip & Reopen
ddrescue -A --retrim -f -i0 -s300GiB /dev/sdc /dev/sdd /home/logfile
'-A' ('--try-again')
Mark all non-trimmed and non-scraped blocks inside the rescue domain as non-tried before beginning the rescue.
Try this if the drive stops responding and ddrescue immediately starts scraping failed blocks when restarted.
If '--retrim' is also specified, mark all failed blocks inside the rescue domain as non-tried.
'--retrim'
Mark all failed blocks inside the rescue domain as non-trimmed before beginning the rescue.
Skip
-n, --no-scrape
# skip the scraping phase
# Avoids spending a lot of time trying to rescue the most difficult parts of the file.
-N, --no-trim
# skip the trimming phase
Example: Recovery to image file
cd /home/recovery
# '-N' skip the trimming phase
# '-n' skip the scraping phase
# -b 4096 4k block
ddrescue -n -N -b 4096 /dev/sdf sdf.img ddrescue.log
# '-d' use direct disc access for input file
ddrescue -d -r 3 -b 4096 /dev/sdf sdf.img ddrescue.log
Notes
# жЯ•зЬЛ status
watch 'dmesg | tail -20'
retry-passes
'-r n' / '--retry-passes=n' # Exit after given number of retry passes. Defaults to 0 (-1=infinity)
дљњзФ®еЊМзФ±
[696330.055065] sd 7:0:0:0: [sde] tag#0 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE [696330.055069] sd 7:0:0:0: [sde] tag#0 Sense Key : Medium Error [current] [696330.055072] sd 7:0:0:0: [sde] tag#0 Add. Sense: Unrecovered read error [696330.055076] sd 7:0:0:0: [sde] tag#0 CDB: Read(10) 28 00 20 88 22 30 00 00 08 00 [696330.055078] print_req_error: critical medium error, dev sde, sector 545792560 [696330.055089] Buffer I/O error on dev sde, logical block 68224070, async page read [696336.077706] sd 7:0:0:0: [sde] tag#0 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE [696336.077711] sd 7:0:0:0: [sde] tag#0 Sense Key : Medium Error [current] [696336.077714] sd 7:0:0:0: [sde] tag#0 Add. Sense: Unrecovered read error [696336.077717] sd 7:0:0:0: [sde] tag#0 CDB: Read(10) 28 00 20 88 22 30 00 00 08 00 [696336.077720] print_req_error: critical medium error, dev sde, sector 545792560 [696336.077731] Buffer I/O error on dev sde, logical block 68224070, async page read
иЃКжИР (ж≤ТжЬЙдЇЖ "Buffer I/O error" еПКйЗНи§ЗдЄАжђ° )
[696419.260665] sd 7:0:0:0: [sde] tag#0 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE [696419.260669] sd 7:0:0:0: [sde] tag#0 Sense Key : Medium Error [current] [696419.260672] sd 7:0:0:0: [sde] tag#0 Add. Sense: Unrecovered read error [696419.260675] sd 7:0:0:0: [sde] tag#0 CDB: Read(10) 28 00 20 8a 97 00 00 00 80 00 [696419.260678] print_req_error: critical medium error, dev sde, sector 545953536
Reopen
-O, --reopen-on-error reopen input file after every read error
Direct disc access (-d)
If you notice that the positions and sizes in the logfile are ALWAYS multiples of the sector size,
maybe your kernel is caching the disc accesses and grouping them.
In this case you may want to use direct disc access to bypass the kernel cache and rescue more of your data.
NOTE! Sector size must be correctly set with the '--sector-size' option for this to work.
# fast reading first ddrescue -f -n /dev/hdb1 /dev/hdc1 logfile # slower than normal cached reading ddrescue -f -d -r3 /dev/hdb1 /dev/hdc1 logfile # fix & mount e2fsck -v -f /dev/hdc1 mount -t ext2 -o ro /dev/hdc1 /mnt
Change Passes
--cpass=range
- 1
- 1,2,3
- 2-4
Logfile Structure
Example:
# Mapfile. Created by GNU ddrescue version 1.23 # Command line: ddrescue -A -n -d /dev/sdf3 dsk2.img dsk2.log # Start time: 2023-11-03 17:09:35 # Current time: 2023-11-03 17:14:41 # Copying non-tried blocks... Pass 1 (forwards) # current_pos current_status current_pass 0x368A14BA00 ? 1 # pos size status 0x00000000 0x00200000 + 0x00200000 0x01CA0000 -
The first non-comment line is the status line.
(The status line allows ddrescue to resume the copying phase instead of restarting it from pass 1)
- The first integer is the position being tried in the input file.
- Status character
- Current pass in the current phase.
Status character
Character Meaning
- '?' copying non-tried blocks
- '*' trimming non-trimmed blocks
- '/' scraping non-scraped blocks
- '-' retrying bad sectors
- 'F' filling specified blocks
- 'G' generating approximate logfile
- '+' finished
The blocks in the list of data blocks
Character Meaning
- '?' # non-tried block
- '*' # failed block non-trimmed
- '/' # failed block non-scraped
- '-' # failed block bad-sectors (bad blocks)
- '+' # finished blocks (good sectors)
Example: Recovery CD
# recovery
ddrescue -n -b2048 /dev/sr0 cd.iso log.txt
ddrescue -d -r 3 -b2048 /dev/sr0 cd.iso log.txt
remark
-b # sector size of input device [default 512]
еЬ® CD жЩВдЄАеЃЪдњВ -b2048
е¶ВжЮЬ errsize дњВ 0 еТБжЮЬйЪї CD е∞±жХСињФдЇЖ.
# Identifying Discs (iso image)
apt-get install genisoimage
isoinfo -d -i /dev/sr0
- -d # Print information from the primary volume descriptor (PVD) of the iso9660 image.
- -i iso_image
# recovery content from CD
mount -o ro,loop -t iso9660 image.iso /mnt/mountpoint
Fill Mode (--fill)
if you use the "--fill" option, ddrescue does not rescue anything.
fill blocks of given types with data (?*/-+l)
Note that in fill mode the input file is always read from position 0.
In fill mode the input file may have any size.
If it is too small, the data will be duplicated as many times as necessary to fill the input buffer.
If it is too big, only the needed data will be read.
i.e.
# fills all areas marked as ‘-’ (bad hardware blocks) with copies of the string "BAD BLOCK"
echo -n "BaDB1K~!" > tmpfile
ddrescue --fill='-' tmpfile sde.img ddrescue.log ddrescue --fill='*' tmpfile sde.img ddrescue.log ddrescue --fill='/' tmpfile sde.img ddrescue.log ddrescue --fill='?' tmpfile sde.img ddrescue.log
Figure out currupt file
1) Copy the damaged drive with ddrescue until finished.
Do not use sparse writes. This yields a logfile with only finished (‘+’) and bad (‘-’) areas.
-S, --sparse # use sparse writes for output file
2) Mount the copied drive (or the image file, via loopback device).
3) Compute a md5sum or other checksum for every file.
Build a list of all the files and their checksums.
4) Fill the bad areas of the copied drive or image file with a byte value different from zero.
5) Verify the checksums. Those files which have different checksums this time reside (at least partially) in damaged disk areas.
ddrescueview
HomePage: http://sourceforge.net/p/ddrescueview
еЃГжШѓдЄАеАЛе∞З mapfile иљЙжИР Graph зЪДй°ѓз§ЇеЈ•еЕЈ
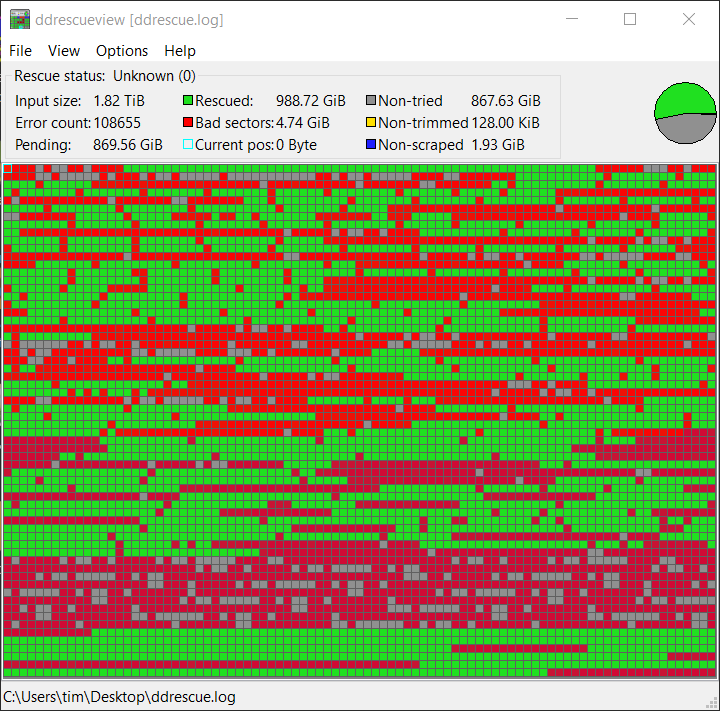
Display Settings
-B, --binary-prefixes # Default: SI prefixes (powers of 1000)
# Show units with binary prefixes (powers of 1024)